FAQ
- What is Contextual Phrase Detection (CPD)? A single task that subsumes object detection, phrase grounding and visual question answering, in which the model must use full context from the given sentence, decide whether this sentence holds true for the given image, and if so, return bounding boxes for all relevant objects referred to in the sentence.
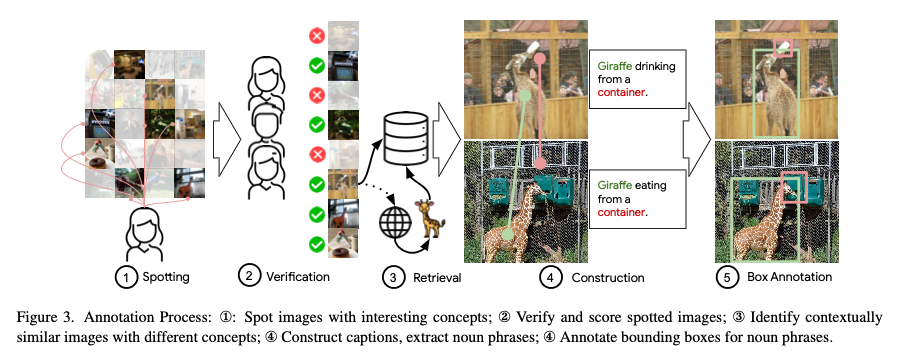
- How is the TRICD dataset different from other benchmarks? : We manually curate image-text pairs with bounding boxes for each of the phrases present in the image. The pairs are contextually related, but partially contradictory; i.e. while the images and texts are semantically similar, each sentence is only depicted in one of the images, but not the other. We manually verify and ensure the negatives.
- But is it really that much harder than existing classification and grounding benchmarks? Yes! We show that by decomposing our task into classification and grounding, we can compare model’s performance on sub-splits of GQA and Flickr30k, and find that our benchmark has a significant gap over these prior benchmarks.
- What is the metric that is used? We compute Average Precision as is common in object detection literature.
- Where do the images come from? We use two data distributions - COCO and Winoground as our pool of images from which we build our dataset.
Abstract
Most traditional benchmarks for computer vision focus on tasks that use a fixed set of labels that are known a priori. On the other hand, tasks like phrase grounding and referring expression comprehension make it possible to probe the model through natural language, which allows us to gain a more extensive understanding of the model’s visual understanding capabilities. However, unlike object detection, these free-form text-conditioned box prediction tasks all operate under the assumption that the text corresponds to objects that are necessarily present in the image. We show that results on such benchmarks tend to overestimate the capabilities of models significantly given that models do not necessarily need to understand the context, but merely localize the named entities. In this work we aim to highlight this blind spot in model evaluation by proposing a novel task: Contextual Phrase Detection (CPD). To evaluate it, we release a human annotated evaluation dataset called TRICD (Testing Robust Image understanding through Contextual Phrase Detection, pronounced “tricked”). It consists of instances of two image-text pairs with bounding boxes for each of the phrases present in the image. The pairs are contextually related, but partially contradictory; i.e. while the images and texts are semantically similar, each sentence is only depicted in one of the images, but not the other. Models must predict the relevant bounding boxes for the phrases in an image if and only if it is in accordance with the context defined by the full sentence. We benchmark the performance of several state of the art multi-modal models on this task in terms of average precision (AP).