Domain Adaptation for Sentiment Analysis
Domain Adaptation
The aim of domain adaptation is to build a classifier such that said classifier trained on a domain (source) can be used to predict in a different domain (target). In particular this can apply to the case where there is plenty of labelled training data available in the source domain and scarce (or no) labelled data in the target domain. When this kind of imabalance is prevalent, good generalisation is very important. In addition, it is often the case that data is distributed very differently in the source and target domains, which presents a major challenge in being able to adapt predictive models.
Supervised machine learning algorithms only perform well when the extensive labelled data has the same distribution as the test data and the test error of supervised methods generlaly grows proportionately to the distance in distributions between the training and test examples.
In this work we examined two existing methods for unsupervised domain adaptation. Unsupervised here is used in the sense that we do not have labels for the target domain.
Stacked Denoising Autoencoders
What is a denoising auto encoder?
An auto-encoder is comprised of an encoder function $e(·)$ and a decoder function $d(·)$, where typically the dimension of encoder’s output is smaller than that of it’s argument. The “hidden” representation that is obtained after applying the encoder function is usually used as a reduced-dimension version of the input. The reconstruction of the input by the auto-encoder is given by $r(x) = d(e(x))$. Typically, when training an auto encoder one trains it to minimize a reconstruction error of the form $loss(x,r(x))$. Auto encoders can be stacked, where the hidden representation of one is given as an input to the next and in this way, once they are trained, their parameters describe several levels of representation of x and can be used to further train a classifier.
A de-noising auto encoder refers to a specific case where the input vector $x$ is corrupted into a vector $\tilde{x}$ using dropout or random gaussian noise and the model is trained to reconstruct $x$ from $\tilde{x}$.
Glorot et al. [3] proposed an approach in which they extract a representation for the training data in an unsupervised manner. They used a two stage pipeline where they first learn a representation of the data and then use a linear classifier for the prediction. The authors empirically determined that the performance was the best when the hidden representation using the auto encoders was built using all the source and target domains for unsupervised pre training as opposed to training on any one domain. In this way, sharing the representations across all domains eradicates the need to repeat this training for a diffeent source to target pair making it easy to scale to larger number of domains.
The stacked denoising auto encoders managed to untwine the elements which explain the varations in the data and at the same time are able to organise them corresponding to their relatedness with these elements. This helps gather useful information about the input data in reduced dimensions. In practice, we used Marginalised Stacked Denoising Auto-Encoders (MSDA) due to the difficulty in training the stacked denoising auto encoders. This method uses linear denoisers as the building blocks which enables the random feature corruption to be marginalised out ensuring that the optimization is convex and is possible to be solved in a closed loop manner.
Correlation Alignment (CORAL)
In the work of Sun et al., they described a method of unsupervised domain adaptation by aligning the second order statistics of source and taget data. They propose in their paper “Return of Frustratingly easy domain adaptation” to first whiten the source features and then re colour the source features with the covariance of the target domain features. This method is useful because it requires very little computation and only deals with the features and can hence be coupled with any kind of classifier.
Dataset used
We used the reduced amazon reviews dataset so that we could compare our results with the existing methods that use the same dataset. It contains reviews of products on Amazon from four different domains : Books, Electronics, Kithchen and DVDs. Each of the domains have only two classes for the sentiment - eithr positive or negative.
Pre-processing of data
The following pre processing is done for the data : “Each review text is treated as a bag-of-words and transformed into binary vectors encoding the presence/absence of unigrams and bigrams. For computational reasons, only the 5000 most frequent terms of the vocabulary of unigrams and bigrams are kept in the feature set.” as mentioned in the paper by Glorot et al. If bag of words features are used using the entire dataset, the results are not reproducible. So we used the same data preprocessing as mentioned in the paper so as to have comparable results.
Our Findings
We performed some data analysis to observe the separability of the data. We used t-sne to get a feel of how separable the data is in its raw state and after applying MSDA and CORAL algorithms. We found that raw BOW features using the whole vocabualry was quite inseparable in that state as opposed to the BOW with the reduced frequent term vocabulary.
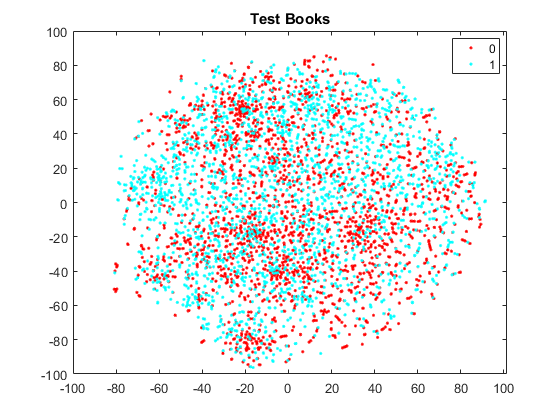
- Books domain data as raw BOW
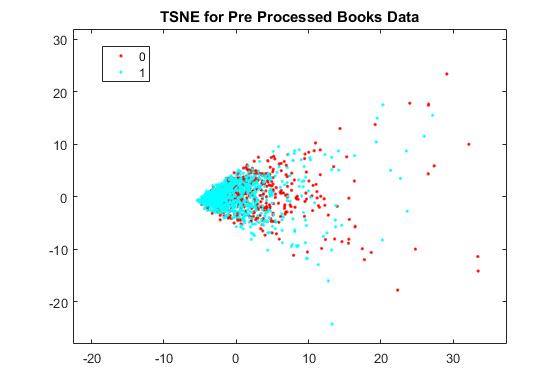
- The same books domain data preprocessed using only 5000 most frequent terms
Further, as compared to the image dataset such as OFFICE-10 dataset where these domain adaptation methods work really well, we could see a stark difference in the separability when compared to the sentiment analysis task. So it made sense why these algorithms would work much better on the OFFICE-10 dataset.
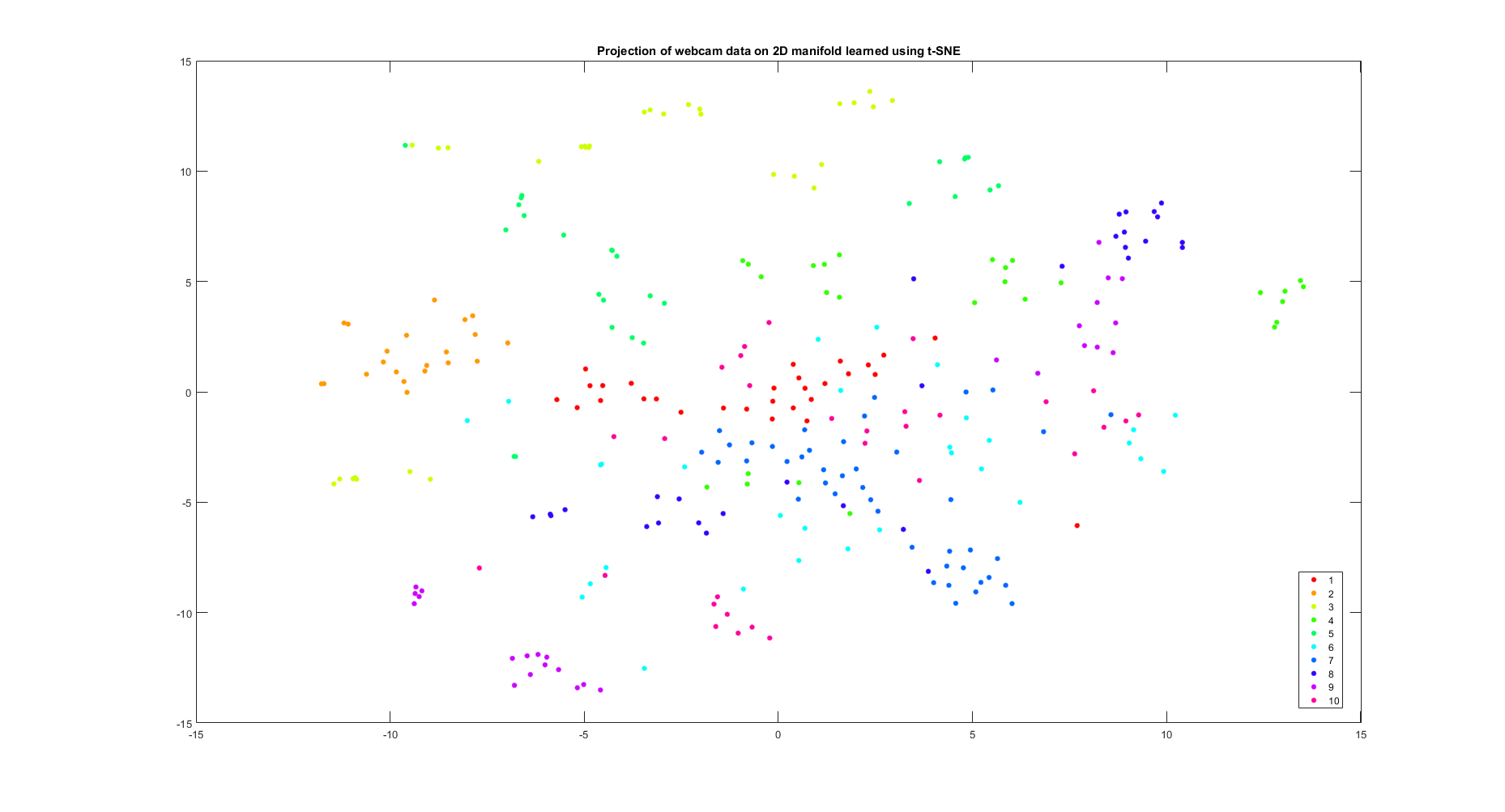
- Webcam domain data from OFFICE-10 image dataset
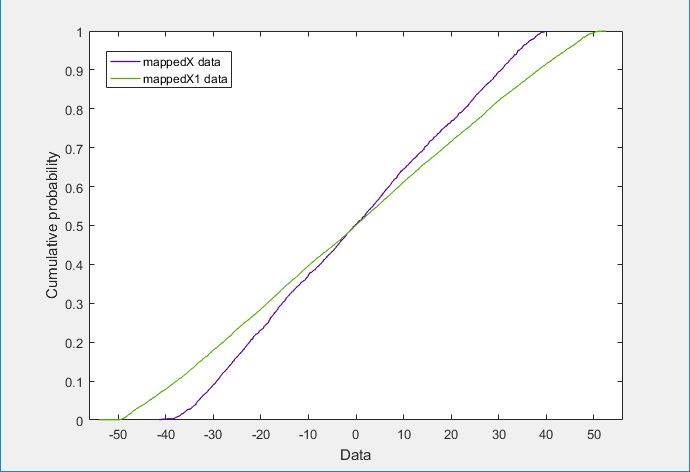
In accordance with the numbers listed in the paper, we observed that the CORAL algorithm only works well and gives gains over the no-adaptation case when there is a stark difference in the distributions of the source and target domain distributions as shown in the figures.
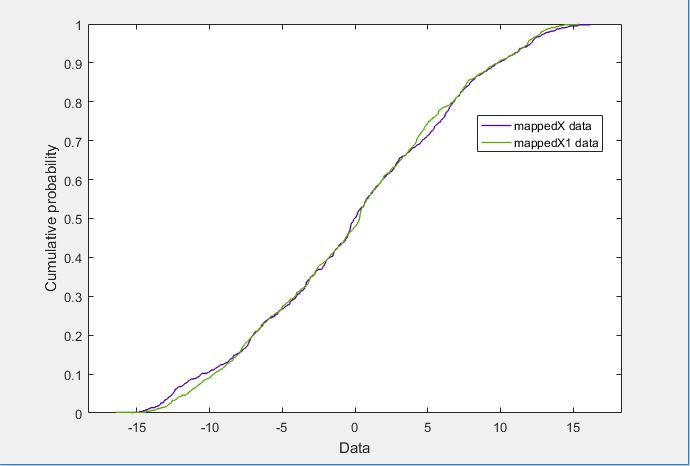
- CDFs of the Kitchen and Electronics domains
- CDFs of the Webcam and DSLR domains
In the case of Kitchen and Electronics, since the distributions are so similar, it does not make much difference as opposed to Webcam and DSLR where the distributions are evidently different. Further strengthening our analysis was that CORAL gave much better results on the Books-Kitchen shift (where the distributions differ a lot) as opposed to the Kitchen-Electronics shift.
- PDFs of the Kitchen and Electronics domains
- PDFs of the Books and Kitchen domains
We next wanted to observe the effects of the MSDA algorithm on the distributions of the domains and we noticed that it does indeed disentangle the hidden features, increasing the distance between the distributions.
- PDFs of the Books and Kitchen domains
- PDFs of the Books and Kitchen domains with MSDA
Proposal
So we proposed to use the MSDA and CORAL algorithms in conjunction by extracting the MSDA features and giving that as input to the CORAL algorithm to see if that improves the ability to adapt across domains. We believe that the two algorithms optimize different objectives and hence should be able to complement each other to obtain superior accuracy when used together. This comes from our understanding that mSDA tries to disentangle features in a lower manifold and coral capitalises on the difference in the distributions of the source and target. So if the mSDA manages to give hidden representation features which increase the difference in the distributions of the source and target domains, CORAL will improve the classification further giving better results than either of the two algorithms.
Results
We obtained the following results which showed that our hypothesis was indeed correct and we got improvement in accuracies in all the domains and these results were comparable to the more recent Domain Adversarial Neural Networks approach towards domain adaptation. We however used only 4 layers in the MSDA due to computational restrictions and used a noise factor of 0.8. We wish to try to extend this to 5 layers and better tune the noise factor hyperparameter.
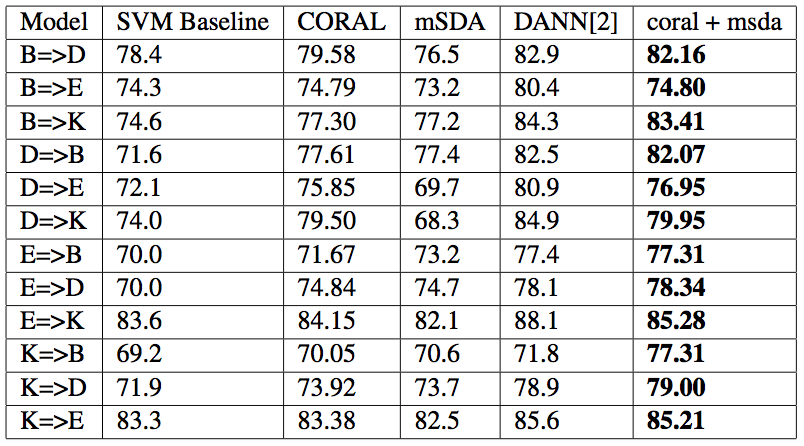
- Results
Future work
We wish to see how the classifier fares by using DANNs along with our current framework.
References
[1] Chen, Minmin, et al. “Marginalized denoising autoencoders for domain adaptation.” arXiv preprint arXiv:1206.4683 (2012).
[2] Ajakan, Hana, et al. “Domain-adversarial neural networks.” arXiv preprint arXiv:1412.4446 (2014).
[3] Glorot, Xavier, Antoine Bordes, and Yoshua Bengio. “Domain adaptation for large-scale sentiment classification: A deep learning approach.” Proceedings of the 28th international conference on machine learning (ICML-11). 2011. APA