About |
|
I am currently joining as a Research Scientist at DeepMind (December 2023) in the Vision Team led by Andrew Zisserman. Previously, I earned my PhD on Fine-Grained Vision and Language Understanding at New York University's Center for Data Science advised by Prof. Yann LeCun and Prof. Kyunghyun Cho. Prior to this I was advised during my Masters by Prof. Andrew McCallum at University of Massachusetts Amherst in areas of natural language processing with a special focus on structured prediction. My current interests lie at the intersection of vision and language, and my research focuses on using information from multiple sources such as text, images, and video to improve reasoning capabilities of machines. Email / CV / Google Scholar / Twitter / Github |

|
News |
Research |
|
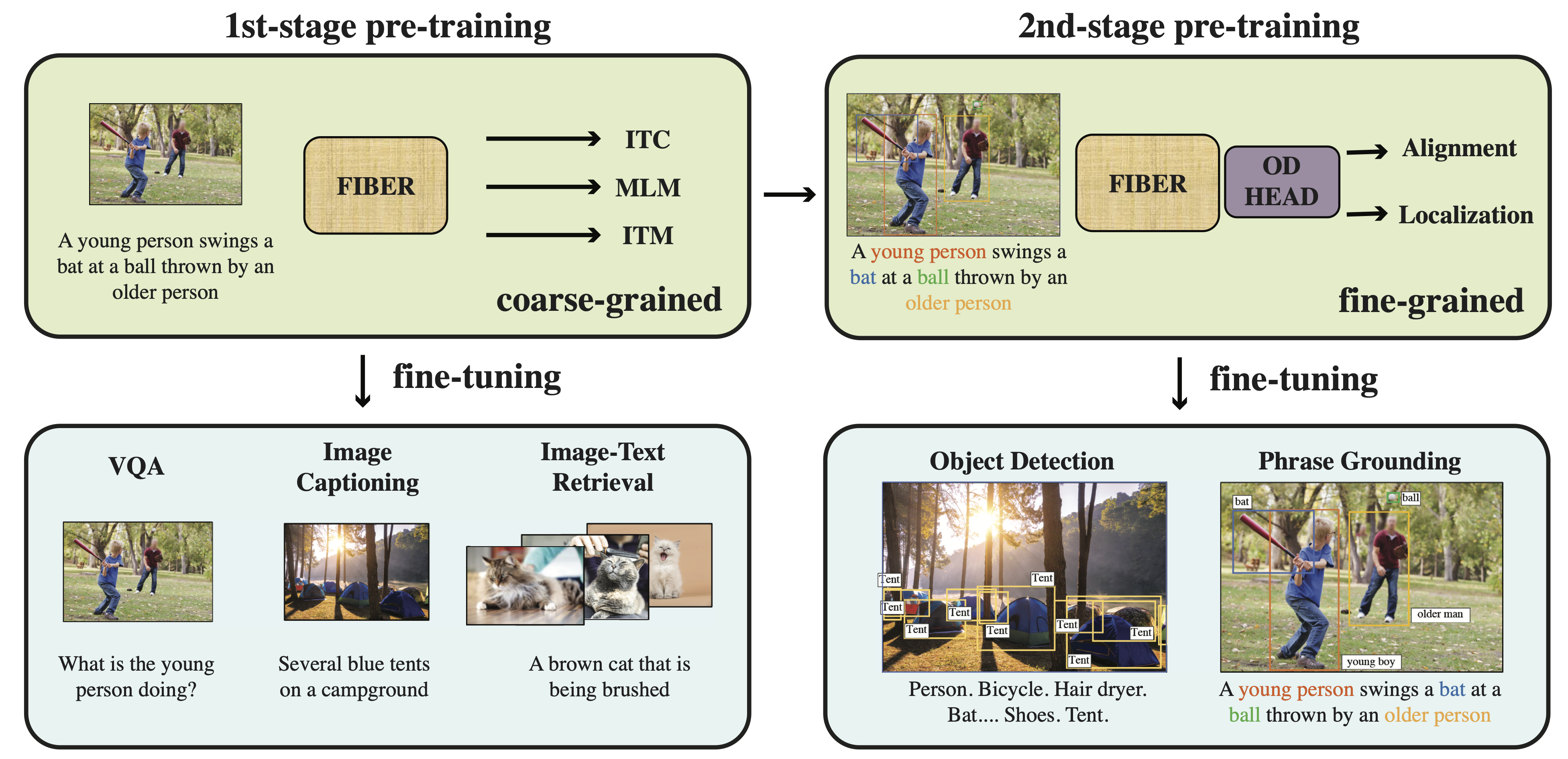
FIBER: Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
Zi-Yi Dou*‡ Aishwarya Kamath*◊, Zhe Gan*† (*equal contribution) Pengchuan Zhang† Jianfeng Wang† Linjie Li† Zicheng Liu† Ce Liu† Yann LeCun◊ Nanyun Peng‡ Jianfeng Gao† Lijuan Wang† NeurIPS 2022 Project page / Paper / Code & Model weights We present FIBER (Fusion In-the-Backbone transformER) a novel Vision and Language architecture that performs deep multi-modal fusion. We also propose a new Vision-Language Pre-training (VLP) strategy, that first learns through coarse-grained image level objectives, and then obtains better fine-grained understanding capabilties by training on image-text-box data. While previous work required pseudo-annotating large amounts of image-text data to boost performance on fine-grained reasoning tasks, we show that we can equal and often surpass these results using our two-stage approach, using 25x less box annotated data. This opens the doors to scale up fine-grained models in an efficient manner without resorting to high resolution training using box annotated data. Our improved architecture also obtains state of the art performance on VQAv2, NLVR2, COCO captioning and Image-text Retrieval while being more efficient in terms of training time and memory than existing coarse and fine-grained models having similar performance. |

|
MDETR - Modulated Detection for End-to-End Multi-modal
Understanding
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, Nicolas Carion ICCV 2021, (Oral Presentation, top 3% of submissions) Project page / Paper / Code & Model weights / Colab We step away from existing approaches to multi-modal understanding that involve frozen pre-trained object detectors trained on a fixed label set, and instead achieve true end-to-end multi-modal understanding by detecting objects that are referred to in free form text. You can now detect and reason over novel combination of object classes and attributes like "a pink elephant"! |
|
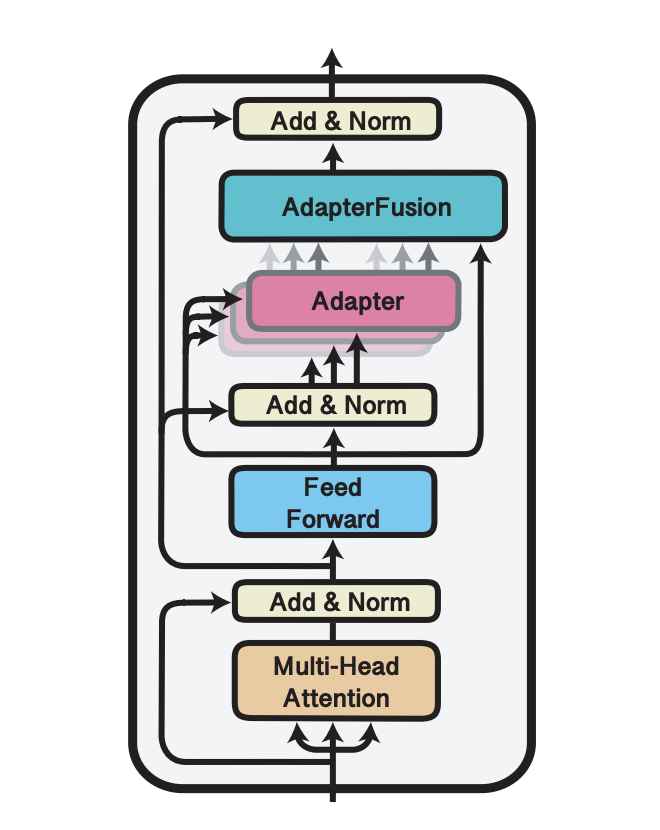
AdapterFusion: Non-Destructive Task Composition for Transfer
Learning
Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, Iryna Gurevych EACL 2021, (Oral Presentation) Project page & Code / Paper / Colab We propose a new transfer learning algorithm that combines skills learned from multiple tasks in a non-destructive manner. |

|
A Survey on Semantic Parsing
Aishwarya Kamath, Rajarshi Das AKBC 2019 Paper A brief history of semantic parsing, with pointers to several seminal works. Check out the poster for a TL;DR. |
|
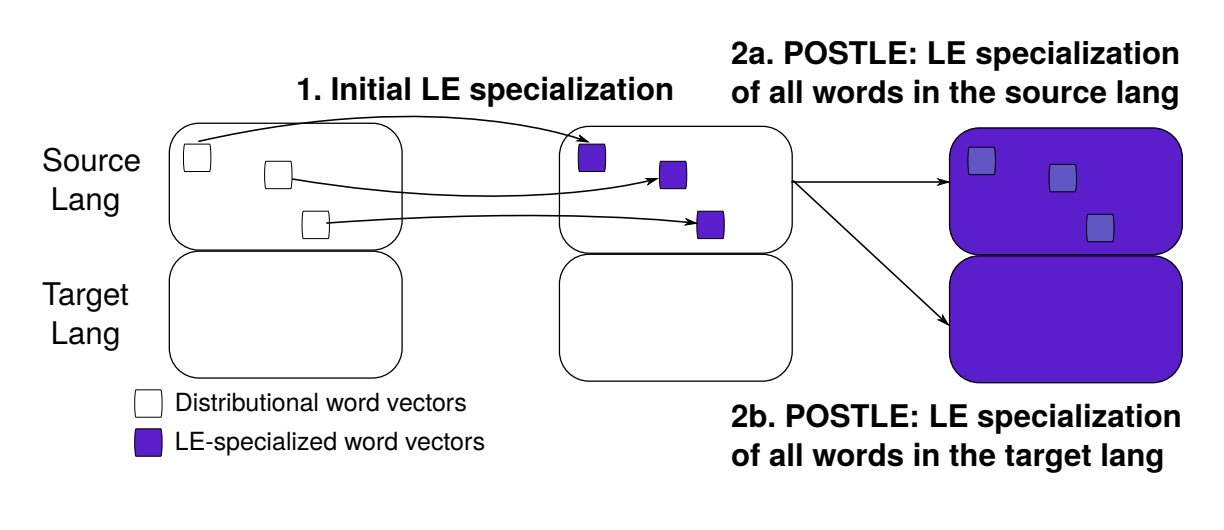
Specializing Distributional Vectors of All Words for Lexical
Entailment
Aishwarya Kamath*, Jonas Pfeiffer*, Edoardo M. Ponti, Goran Glavaš, , Ivan Vulic´ Representation Learning for NLP Workshop, ACL 2019, (Best Paper Award) Paper We present the first word embedding post-processing method that specializes vectors of all vocabulary words – including those unseen in the resources – for the asymmetric relation of lexical entailment (LE) (i.e., hyponymy-hypernymy relation). We report consistent gains over state-of-the-art LE-specialization methods, and successfully LE-specialize word vectors for languages without any external lexical knowledge. |
|
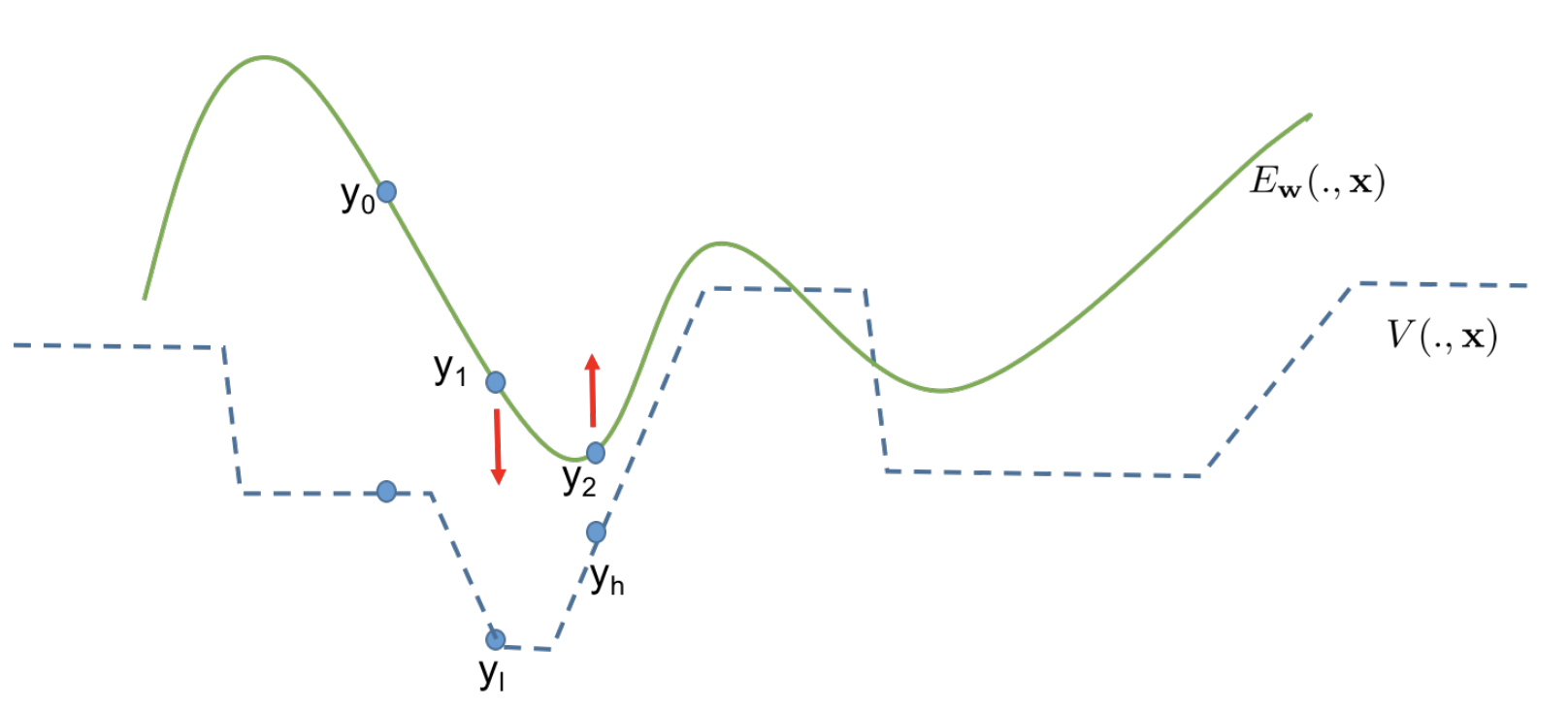
Training Structured Prediction Energy Networks with Indirect
Supervision
Amirmohammad Rooshenas, Aishwarya Kamath, Andrew McCallum, NAACL 2018, (Oral Presentation) Paper We train a structured prediction energy network (SPEN) without any labeled data instances, where the only source of supervision is a simple human-written scoring function. |
Awards |
Academic Service |
Teaching |