Abstract
Most multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes. This makes it challenging for such systems to capture the long tail of visual concepts expressed in free form text. In this paper we propose MDETR, an end-to-end modulated detector that detects objects in an image conditioned on a raw text query, like a caption or a question. We use a transformer-based architecture to reason jointly over text and image by fusing the two modalities at an early stage of the model. We pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image. We then fine-tune on several downstream tasks such as phrase grounding, referring expression comprehension and segmentation, achieving state-of-the-art results on popular benchmarks. We also investigate the utility of our model as an object detector on a given label set when fine-tuned in a few-shot setting. We show that our pre-training approach provides a way to handle the long tail of object categories which have very few labelled instances. Our approach can be easily extended for visual question answering, achieving competitive performance on GQA and CLEVR.
TL;DR
- We achieve true end-to-end multi-modal understanding by training the object detector in the loop.
- Only detect objects that are relevant to the given text query, and predict the corresponding spans for each object in the text.
- Allows us to expand our vocabulary to anything found in free form text
- We can now detect and reason over novel combination of object classes and attributes like "a pink elephant" shown below!
Main results
Phrase Grounding on Flickr 30k entities
The Flickr 30k entities dataset consists of captions where constituent phrases in each caption are annotated with one or more bounding boxes corresponding to the referred objects in the image. MDETR is trained to detect all referred objects by conditioning on the text. We report Recall@k under the "ANY-BOX" protocol, see the paper for more details. These results are obtained directly from the pre-trained model, with no additional finetuning required.
| Backbone | Val R@1 | Val R@5 | Val R@10 | Test R@1 | Test R@5 | Test R@10 |
|---|---|---|---|---|---|---|
| Resnet-101 | 82.5 | 92.9 | 94.9 | 83.4 | 93.5 | 95.3 |
| EfficientNet-B3 | 82.9 | 93.2 | 95.2 | 84.0 | 93.8 | 95.6 |
| EfficientNet-B5 | 83.6 | 93.4 | 95.1 | 84.3 | 93.9 | 95.8 |
Some qualitative results

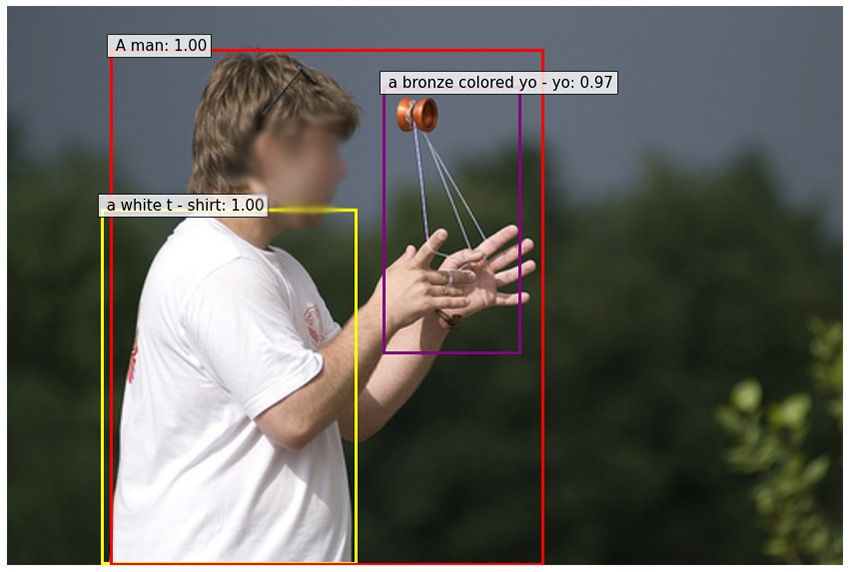
Referring Expressions on RefCOCO, RefCOCO+ and RefCOCOg
Referring expression comprehension consists of finding the bounding box corresponding to a given sentence. MDETR casts this as a modulated detection task where the model directly predicts the bounding box described by the entire sentence. We report the accuracy on validation and test sets of popular benchmarks, after a few epochs of finetuning on each dataset. See paper for more details.
| Backbone | Val | TestA | TestB |
|---|---|---|---|
| Resnet-101 | 86.75 | 89.58 | 81.41 |
| EfficientNet-B3 | 87.51 | 90.40 | 82.67 |
| Backbone | Val | TestA | TestB |
|---|---|---|---|
| Resnet-101 | 79.52 | 84.09 | 70.62 |
| EfficientNet-B3 | 81.13 | 85.52 | 72.96 |
| Backbone | Val | Test |
|---|---|---|
| Resnet-101 | 81.64 | 80.89 |
| EfficientNet-B3 | 83.35 | 83.31 |
Some qualitative results



Referring Expression Segmentation on PhraseCut
PhraseCut is a referring expression segmentation dataset. We illustrate that, similarly to DETR, MDETR can be easily extented to perform segmentation. We first finetune the model for modulated detection on PhraseCut, by predicting all boxes corresponding to the referring expression. We then freeze the model and train a segmentation head for 30 epochs. We report the Mean-IOU as well as precision at various IoU thresholds. See paper for more details.
| Backbone | M-IoU | P@0.5 | P@0.7 | P@0.9 |
|---|---|---|---|---|
| Resnet-101 | 53.1 | 56.1 | 38.9 | 11.9 |
| EfficientNet-B3 | 53.7 | 57.5 | 39.9 | 11.9 |


Visual Question Answering on GQA
We show that MDETR can be used for downstream tasks beyond modulated detection. We experiment on GQA, a challenging visual question answering dataset. We finetune on GQA-all for 5 epochs followed by GQA-balanced for 10.
| Backbone | Test-dev | Test-std |
|---|---|---|
| Resnet-101 | 62.48 | 61.99 |
| EfficientNet-B3 | 62.95 | 62.45 |
Long-tailed few-shot object detection on LVIS
We show that vision+language pre-training in the modulated detection framework is beneficial for long tail object detection. We finetune MDETR on a subsets of LVIS in a fewshot setting, and show that the model performs well, even on rare categories (APr). We report the box AP fixed. See paper for more details.
| Data | AP | AP 50 | APr | APc | APf |
|---|---|---|---|---|---|
| 1% | 16.7 | 25.8 | 11.2 | 14.6 | 19.5 |
| 10% | 24.2 | 38.0 | 20.9 | 24.9 | 24.3 |
| 100% | 22.5 | 35.2 | 7.4 | 22.7 | 25.0 |